
A new study from Lenz Research shows that five leading AI models-GPT-5.4, Claude Opus 4.7, Gemini 3 Pro, Gemini 3 Pro with Search, and Sonar Pro-disagreed on 67% of 1,000 real-world fact-check claims.
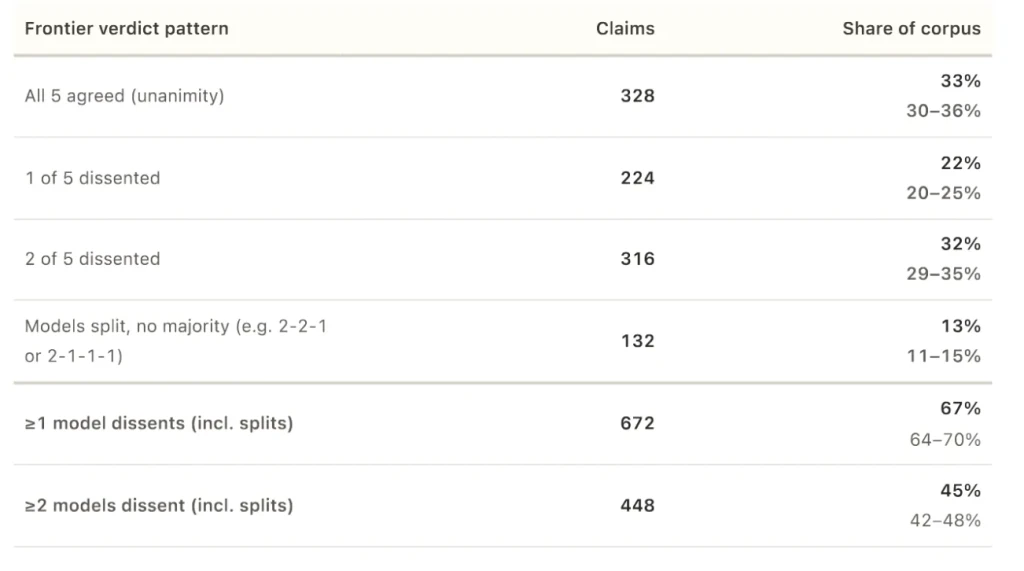
Researcher Kosta Jordanov tested the systems on claims submitted by actual users to a fact-checking platform. On 672 out of 1,000 claims, at least one model broke from the majority. In 34% of cases, one model called a claim true while another called it false.
The agreement score, known as Krippendorff's alpha, was 0.639-well below the 0.8 threshold considered reliable. Unanimous agreement occurred on only 328 claims, and almost exclusively at the extremes: definitely true or definitely false. Not one claim received a unanimous “mostly true” verdict, and only four received unanimous “misleading.”
The researchers used user-submitted claims specifically to avoid benchmark data leaking into the models' training sets. As the study notes: there is no canonical answer key for these real-world statements.
The instability raises serious questions about relying on AI for fact-checking. One example claim-"The World Bank's active portfolio in Nigeria stands at over $16.4 billion as of 2025"-drew three different verdicts from three models. Another about a Trump statement on Iran received a range from “true” to “false” across the five systems.
The study's authors caution that the majority verdict is not necessarily ground truth. But when models disagree, at least one of them must be wrong-and there is no process to determine which.