If you’re an aspiring AI professional, becoming an LLM engineer offers an exciting and promising career path.
But where should you start? What should your trajectory look like? How should you learn?
In one of my previous posts, I laid out the complete roadmap to become an AI / LLM Engineer. Reading this article will give you insights into the types of skills you’ll need to acquire and how to start learning.
The Best Way to Learn is to BUILD!
As Andrej Karpathy puts it:

Andrej emphasizes that you should build concrete projects, and explain everything you learn in your own words. (He also instructs us to only compare ourselves to a younger version of ourselves – never to others.)
And I agree – building projects is the best way to not just learn but really grok these concepts. It will further sharpen the skills you’re learning to think about cutting edge use cases.
But the main challenge with this learning philosophy is that good projects can be hard to find.
And that’s the problem I am trying to resolve. I want to help people, including myself, discover and build practical and real-world projects that help you develop skills that are worth showcasing in your portfolio.
Here’s What We’ll Cover:
What Should Be Your First Project?
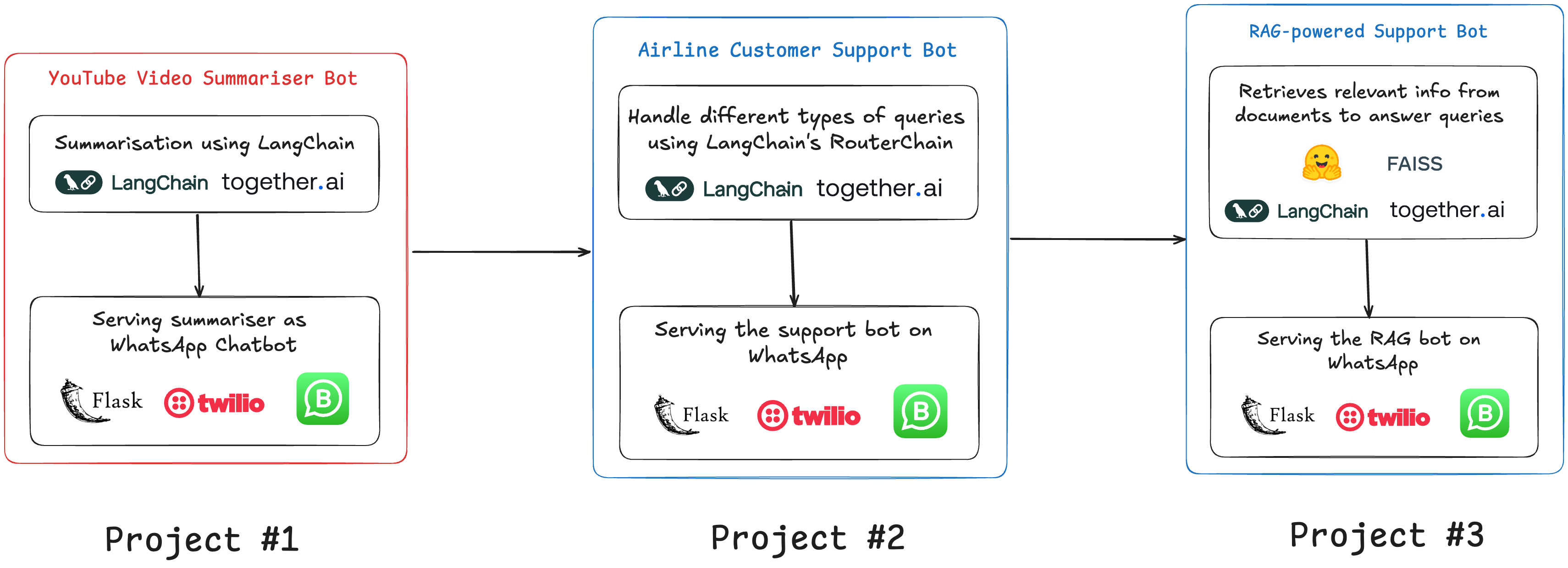
Project #1: YouTube Video Summarizer
Setup and Requirements
Introduction to Document Loaders
Processing YouTube Transcripts
Using LangChain for Summarization
Deploying the Summarizer on WhatsApp
Creating a Flask API
Connecting with Twilio for WhatsApp integration
Project #2 preview: Multi-purpose Customer Service Bot
Project #3 preview: RAG-Powered Support Bot
Conclusion
What Should Be Your First Project?
If you’re a beginner who knows basic to intermediate programming, your initial projects should showcase that you can comfortably build applications with LLMs.
They should demonstrate that:
you know what APIs are
you know how to consume them
you know how to build products that people actually want to use
Building a chatbot provides a great starting point, but at this point everyone has developed one. And there are many solutions for easy Streamlit based prototypes. So, you need to develop something that’s actually usable and has the potential to reach a wider audience.
I’d suggest building a chatbot for WhatsApp or Discord or Telegram. Build a chatbot which solves a problem people struggle with, a problem that companies have started to build solutions for.
If I had to pick a good and, arguably, the most common AI project that every company has started to work on, it would be RAG-powered chatbots.
But before you get to building RAG-powered bots, you should start building something slightly more basic but practical with LLMs.
To kick things off, let’s start by building a YouTube Summariser.
Project #1: Summarise YouTube Videos
We’ll build the first part of this project in this tutorial: the core functionality of a YouTube video summariser tool.
Our bot will:
Receive the YouTube URL.
Validate if the URL is correct.
Retrieve the transcript of the video
Use an LLM to analyze and summarize the video’s content.
Return the summary to the user.
Setup and Requirements
For this project, we’ll code the core functionality in a Jupyter Notebook using the following Python packages:
langchain-together— for the LLM using the LangChain <> Together AI integrationlangchain-community— for specific data loaderslangchain— for programming with LLMspytube— for fetching video infoyoutube-transcript-api— for youtube video transcript
We’ll use the Llama 3.1 model offered as an API by Together AI.
Together AI is a cloud platform that offers the open source models as inference APIs. without worrying about the underlying infrastructure.
Let’s start by installing these:
!pip install — upgrade — quiet langchain
!pip install — quiet langchain-community
!pip install — upgrade — quiet langchain-together
!pip install youtube_transcript_api
!pip install pytube
Now let’s set up our LLM:
## setting up the language model
from langchain_together import ChatTogether
import api_key
llm = ChatTogether(api_key=api_key.api,temperature=0.0,
model="meta-llama/Meta-Llama-3.1-8B-Instruct-Turbo")
The next step is to process the YouTube videos as a data source. For this we’ll need to understand the concept of document loaders.
Introduction to Document Loaders
Document loaders provide a unified interface to load data from various sources into a standardized Document format.
They automatically extract and attach relevant metadata to the loaded content.
The metadata can include source information, timestamps, or other contextual data that can be valuable for downstream processing.
LangChain offers loaders for CSV, PDF, HTML, JSON, and even specialized loaders for sources like YouTube transcripts or GitHub repositories, as listed in their integrations page.
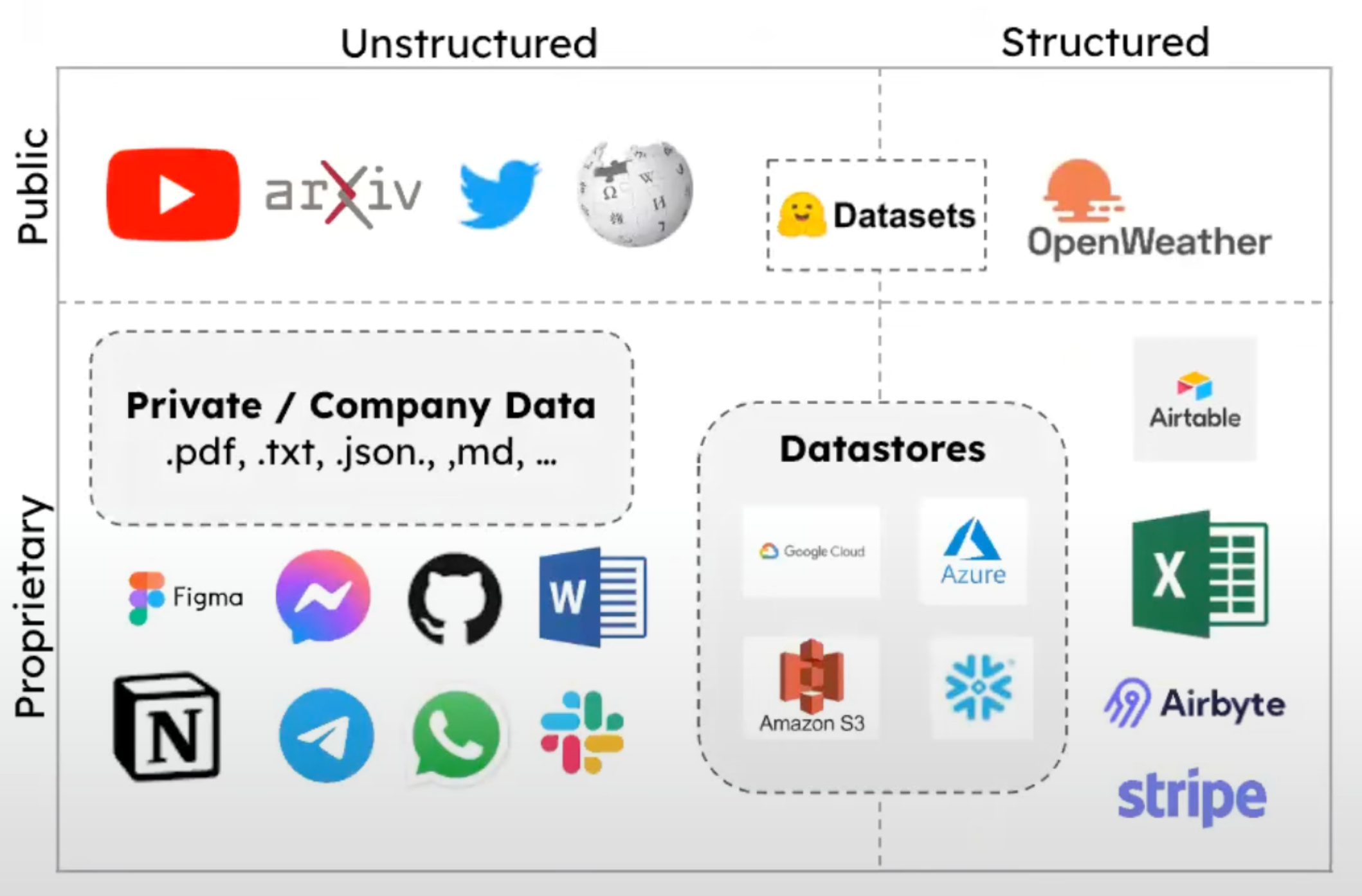
Categories of Document Loaders
Document loaders in LangChain can be broadly categorized into two types:
- File Type-Based Loaders
Parse and load documents based on specific file formats
Examples include: CSV, PDF, HTML, Markdown
2. Data Source-Based Loaders
Retrieve data from various external sources
Load the data into Document objects
Examples include: YouTube, Wikipedia, GitHub
Integration Capabilities
LangChain’s document loaders can integrate with almost any file format you might need.
They also support many third-party data sources.
For our project, we’ll use the YoutubeLoader to get the transcripts in the required format.
YoutubeLoader from LangChain to Get Transcript:
## import the youtube documnent loader from LangChain
from langchain_community.document_loaders import YoutubeLoader
video_url = 'https://www.youtube.com/watch?v=gaWxyWwziwE'
loader = YoutubeLoader.from_youtube_url(video_url, add_video_info=False)
data = loader.load()
Process the YouTube Transcript
Display raw transcript content
Use the LLM to summarize and extract key points from the transcript:
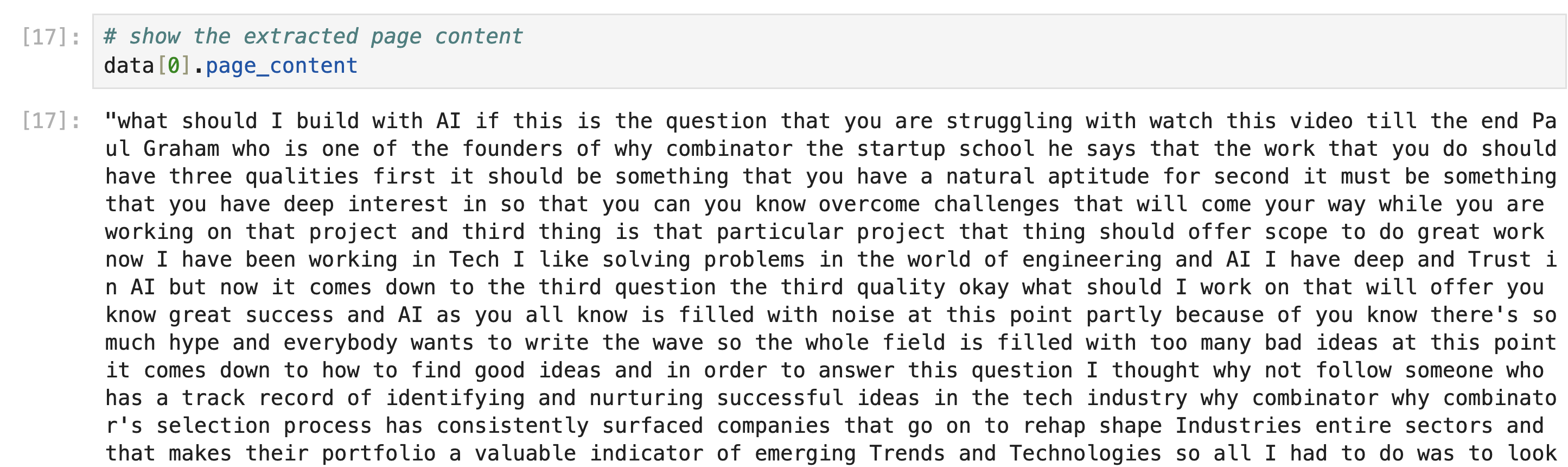
# show the extracted page content
data[0].page_content
The page_content attribute contains the complete transcript as shown in the output below:
Now that we have the transcript, we simply need to pass this to the LLM we configured above along with the prompt to summarise.
First, let’s understand a simple method:
Langchain offers the invoke() method to which you need to pass the system message and the user or human message.
The system message is essentially the instructions for the LLM on how it is supposed to process the human request.
And the human message is simply what we want the LLM to do.
# This code creates a list of messages for the language model:
# 1. A system message with instructions on how to summarize the video transcript
# 2. A human message containing the actual video transcript
# The messages are then passed to the language model (llm) for processing
# The model's response is stored in the 'ai_msg' variable and returned
messages = [
(
"system",
"""Read through the entire transcript carefully.
Provide a concise summary of the video's main topic and purpose.
Extract and list the five most interesting or important points from the transcript. For each point: State the key idea in a clear and concise manner.
- Ensure your summary and key points capture the essence of the video without including unnecessary details.
- Use clear, engaging language that is accessible to a general audience.
- If the transcript includes any statistical data, expert opinions, or unique insights, prioritize including these in your summary or key points.""",
),
("human", data[0].page_content),
]
ai_msg = llm.invoke(messages)
ai_msg
But this method won’t work when you have more variables and when you want a more dynamic solution.
For this, LangChain offers PromptTemplate:
A PromptTemplate in LangChain is a powerful tool that helps in creating dynamic prompts for large language models (LLMs). It allows you to define a template with placeholders for variables that can be filled in with actual values at runtime.
This helps in managing and reusing prompts efficiently, ensuring consistency and reducing the likelihood of errors in prompt creation.
A PromptTemplate consists of:
Template String: The actual prompt text with placeholders for variables.
Input Variables: A list of variables that will be replaced in the template string at runtime.
# Set up a prompt template for summarizing a video transcript using LangChain
# Import necessary classes from LangChain
from langchain.prompts import PromptTemplate
from langchain import LLMChain
# Define a PromptTemplate for summarizing video transcripts
# The template includes instructions for the AI model on how to process the transcript
product_description_template = PromptTemplate(
input_variables=["video_transcript"],
template="""
Read through the entire transcript carefully.
Provide a concise summary of the video's main topic and purpose.
Extract and list the five most interesting or important points from the transcript.
For each point: State the key idea in a clear and concise manner.
- Ensure your summary and key points capture the essence of the video without including unnecessary details.
- Use clear, engaging language that is accessible to a general audience.
- If the transcript includes any statistical data, expert opinions, or unique insights,
prioritize including these in your summary or key points.
Video transcript: {video_transcript} """
)
How to Use LLMChain / LCEL for Summarization
A chain is a sequence of steps that consists of a language model, PromptTemplate, and an optional output parser.
Create an LLMChain with the custom prompt template
Generate a summary of the video transcript using the chain
Here, we are using LLMChain but you can also use LangChain Expression Language as well to do this:
## invoke the chain with the video transcript
chain = LLMChain(llm=llm, prompt=product_description_template)
# Run the chain with the provided product details
summary = chain.invoke({
"video_transcript": data[0].page_content
})
This will give you the summary object which has the text attribute that contains the response in markdown format.
summary['text']
The raw response will look like this:

To see the Markdown formatted response:
from IPython.display import Markdown, display
display(Markdown(summary['text']))
And there you go:

So, the core functionality of our YouTube summariser is now working.
But this is working in your Jupyter Notebook, to make it more accessible, we’d need to get this functionality deployed on WhatsApp.
How to serve the YT summariser on WhatsApp

For this, we’d need to serve our YT summarisation functionality as an API endpoint for which we are going to use Flask. You can also use FastAPI.
Now we’ll turn all the code in the Jupyter notebook into functions. So, add a function to check if it is a valid youtube URL, then define the summarise function that is basically a compilation of what we wrote in the Jupyter notebook.
You can configure our endpoint in the following manner:
@app.route('/summary', methods=['POST'])
def summary():
url = request.form.get('Body') # Get the JSON data from the request body
print(url)
if is_youtube_url(url):
response = summarise(url)
else:
response = "please check if this is a correct youtube video url"
print(response)
resp = MessagingResponse()
msg = resp.message()
msg.body(response)
return str(resp)
Once your app.py is ready with your Flask API, run the Python script, and you should have your server running locally on your system.
The next step is to make your local server connect with WhatsApp, and that’s where we’ll use Twilio.
Twilio allows us to implement this handshake by offering a WhatsApp sandbox to test your bot. You can follow the steps in this guide here to build this connection.
I got the connection established:
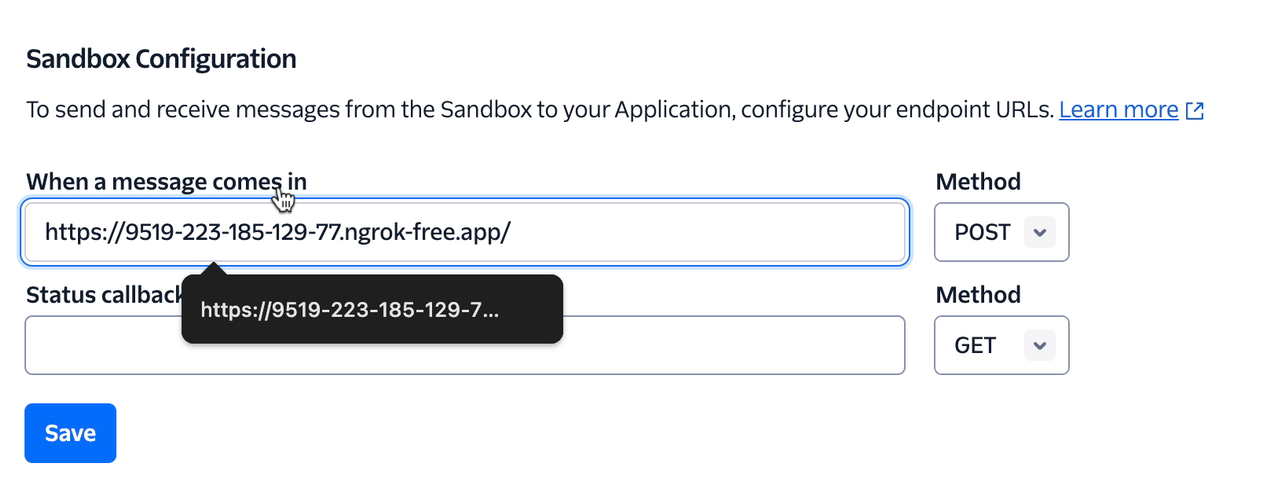
Now, we can start testing our WhatsApp bot:
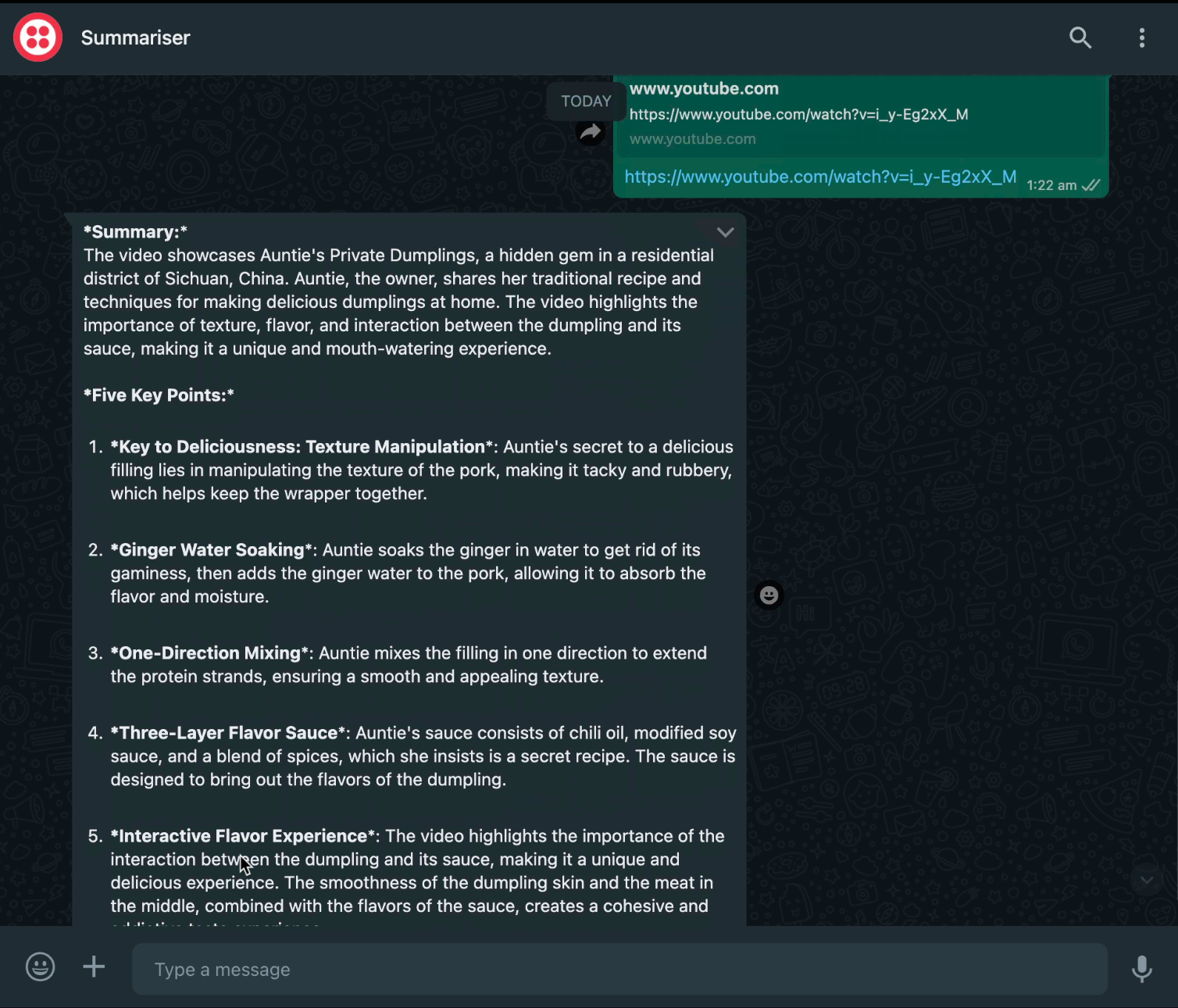
Amazing!
I explain all the steps in detail in my project-based course on Building LLM-powered WhatsApp Chatbots.
It’s a 3-project course that contains two other more complex projects. I’ll give you a brief summary of those other projects here so you can try them out for yourselves. And if you’re interested, you can check out the course as well.
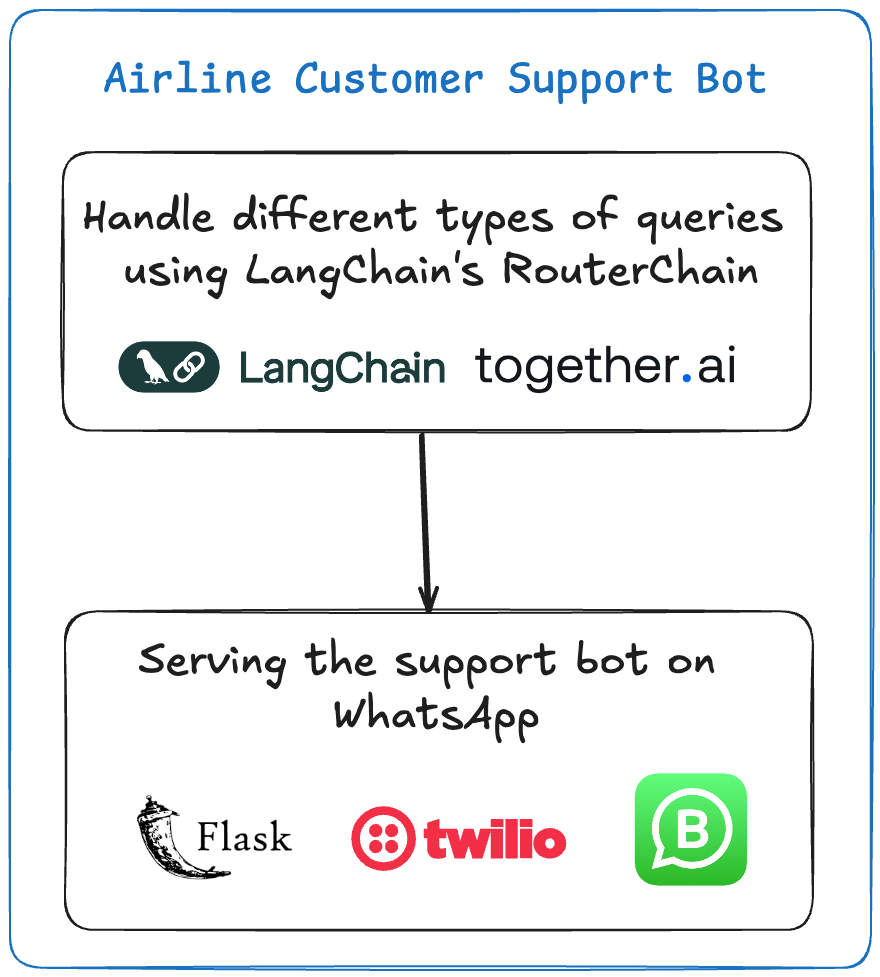
Project #2 — Build a Bot that Can Handle Different Types of User Queries
This bot acts as a customer service representative for an airline. It can answer questions related to flight status, baggage inquiries, ticket booking, and more. It uses Langchain’s Router and LLM models to dynamically generate responses based on the user’s input.
Different prompt templates are defined for various customer queries, such as flight status, baggage inquiries, and complaints.
Based on the query, the router selects the appropriate template and generates a response.
Twilio then sends the response back to the WhatsApp chat.
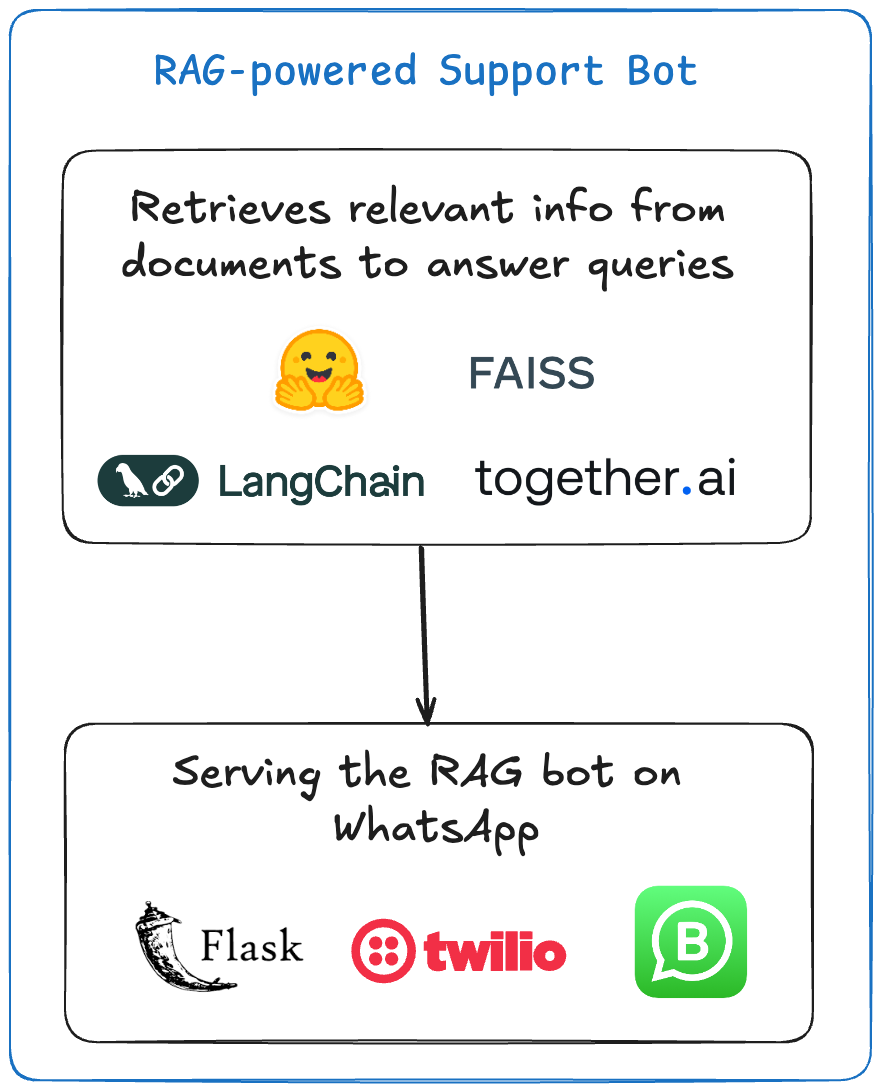
Project #3 — RAG-Powered Support Bot
This chatbot answers questions related to airline services using a document-based system. The document is converted into embeddings, which are then queried using Langchain’s RAG system to generate responses. Companies want developers these days who have these skills, so this is an especially practical project.
The guidelines/rules document is embedded using FAISS and HuggingFace models.
When a user submits a question, the RAG system retrieves relevant information from the document.
The system then generates a response using a pre-trained LLM and sends it back via Twilio.
These 3 projects will get you started so you can continue experimenting and learning more about AI engineering.
Customer Support is the most funded category in AI because it reduces the cost instantly if AI can handle communication with disgruntled users.
So, we build bots that can handle different types of queries, intelligent RAG powered bots which will have access to proprietary documents to provided up-to-date information to the users.
That’s why I created this project-based course to help you start building with LLMs.
Check out the course preview here:
And to thank you for reading this guide, you can use the code FREECODECAMP to get a 20% discount on my course.
I want to make this affordably accessible for all those who are sincere about building with AI, so I’ve priced it affordably at $14.99 USD.
Conclusion
In this tutorial, we focused on building a fun YouTube video summarizer tool that is served on WhatsApp.
The bot's core functionality includes:
Receiving a YouTube URL
Validating the URL
Retrieving the video transcript
Using an LLM to summarize the content
Returning the summary to the user
We used a number of Python packages including langchain-together, langchain-community, langchain, pytube, and youtube-transcript-api.
The project uses the Llama 3.1 model via Together AI's API.
We built the core summarisation functionality using
Using LangChain's invoke() method with system and human messages
Using PromptTemplate and LLMChain for more dynamic solutions
To make the tool accessible via WhatsApp:
The functionality is served as an API endpoint using Flask
Twilio is used to connect the local server with WhatsApp
A WhatsApp sandbox is used for testing the bot
To continue building further projects, check out the course.
It is a beginner track course where you start from learning to build with LLMs, then apply those skills to build 3 different types of LLM applications. Not just that – you learn to serve your applications as WA chatbots.