Alibaba has launched Qwen 3.5 Omni, the first AI model capable of native, real-time processing of text, audio, video, and speech-all simultaneously. Unlike competitors that stitch together separate systems, Qwen 3.5 Omni handles multimodal inputs in a single pass, reducing latency and improving coherence.
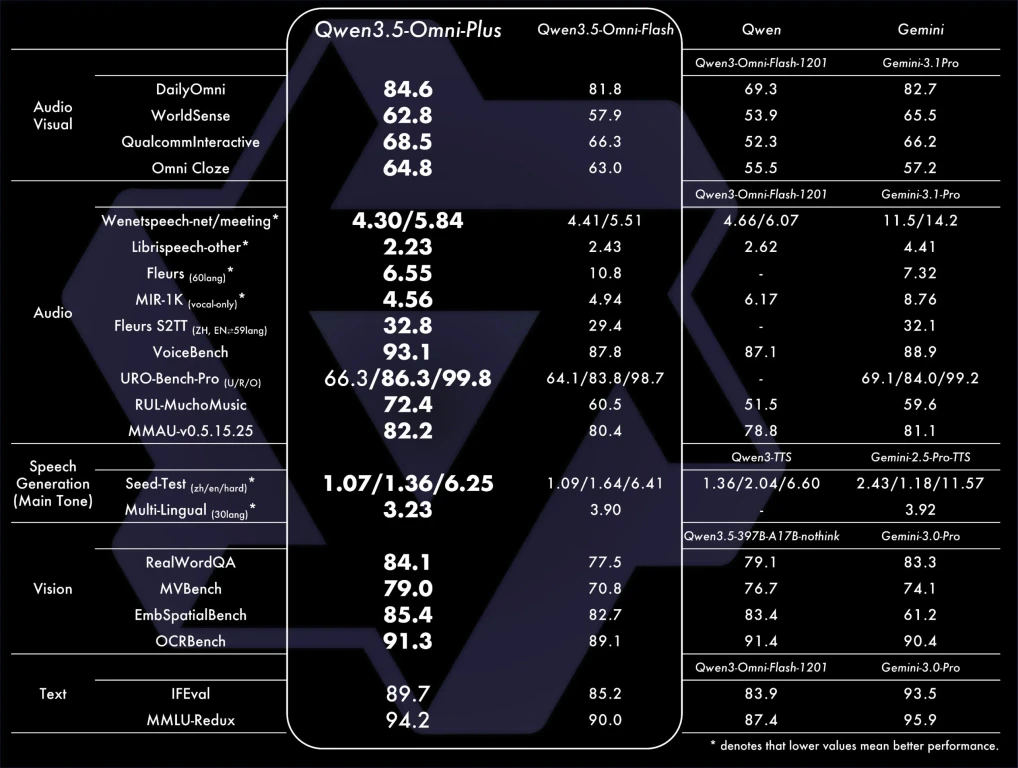
The model supports 113 languages and dialects, outperforms Gemini 3.1 Pro in audio understanding, and matches it in audio-visual comprehension. It can interpret video clips-including speech, visuals, and on-screen text-without external tools, delivering analysis in under a minute where rivals take nine.
A breakthrough feature, Semantic Interruption, allows the AI to distinguish between background noise and intentional user input, enabling natural, human-like conversations. ARIA technology ensures flawless spoken output, even with numbers and technical terms.
Voice cloning is now integrated, letting users replicate any voice for AI responses, directly challenging ElevenLabs. On multilingual benchmarks, Qwen 3.5 Omni Plus surpassed leading voice models across 20 languages.
It also introduces Audio-Visual Vibe Coding: watching a screen recording of a coding task and generating functional code without a single text prompt.
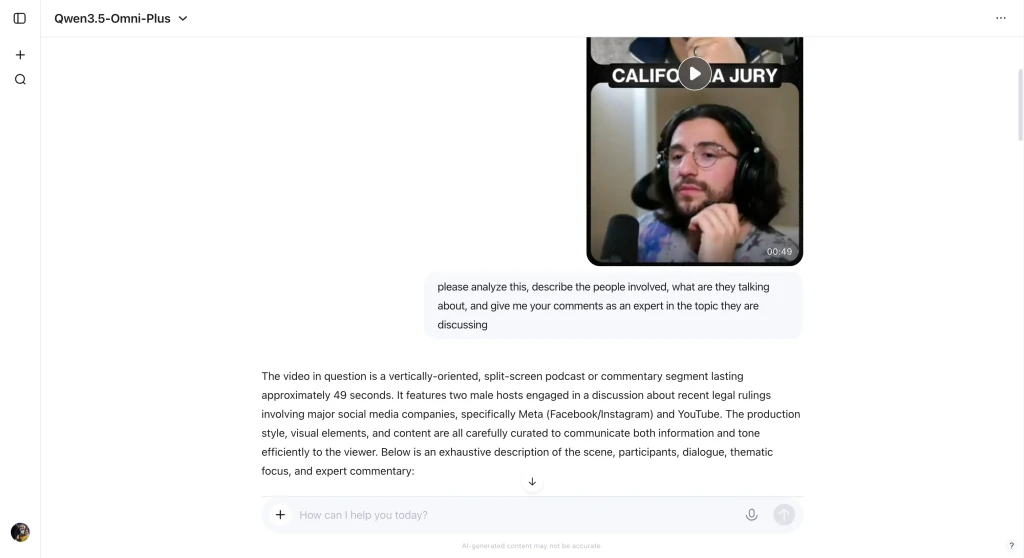
Available via Alibaba Cloud API, the model comes in three variants-Plus, Flash, and Light-with a 256,000-token context window. This is Alibaba’s second major AI release in six weeks, extending its rapid ascent in the global AI race.