
Shanghai-based AI lab StepFun has released StepAudio 2.5 Realtime, an end-to-end real-time voice model that processes audio input directly without text conversion. Supporting Chinese and English, the model claims first place across all five voice AI benchmarks tested in April 2026, beating both GPT Realtime 1.5 and Gemini Live.
StepFun addressed a common AI failure mode-out-of-character behavior under pressure-using roleplay-specific reinforcement learning from human feedback. The training began with over 10,000 human-authored persona seeds, expanded into a million-scale feature matrix to maintain character consistency even in long-tail conversations.
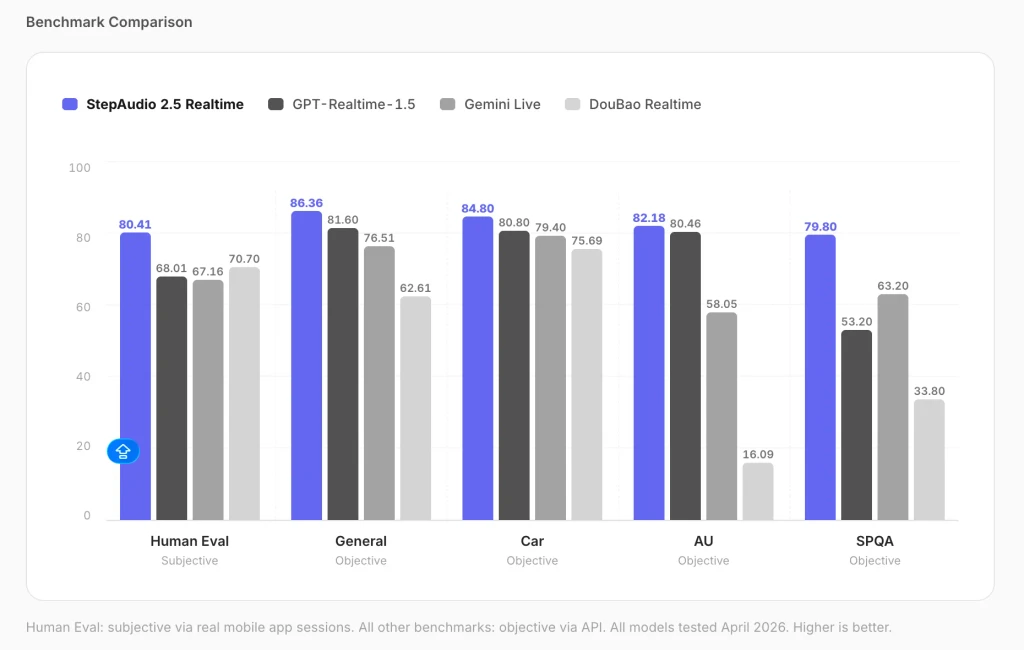
The model's paralinguistic comprehension, which reads vocal cues like speed, emotion, and age directly from audio, scored 82.18 on the benchmark. GPT Realtime 1.5 scored 80.46, while Gemini Live hit 58.05. On human evaluation, StepAudio scored 80.41 versus 68.01 for GPT Realtime 1.5 and 67.16 for Gemini Live. General dialogue quality reached 86.36 compared to GPT's 81.60.
StepFun was founded in April 2023 by Jiang Daxin, a 16-year Microsoft veteran who led projects including Bing, Cortana, and Azure cognitive services. The company is one of China's AI Tiger startups and has raised approximately $1.7 billion to date.
The launch includes a flagship AI persona called Xiao Yue, described as a "soul-level companion" with fully configurable opinions, catchphrases, and emotional limits. Developers can build custom personas via the API.