
A U.S. government institute issued a verdict on China’s most powerful AI: eight months behind, with the gap expected to widen. The Center for AI Standards and Innovation at NIST released its evaluation of DeepSeek V4 Pro on May 1, concluding it lags behind the frontier by roughly eight months.
CAISI uses Item Response Theory to score models across seven benchmarks in five domains. The Elo scores: GPT-5.5 at 1,260, Claude Opus 4.6 at 999, DeepSeek V4 Pro around 800, close to GPT-5.4 mini at 749.
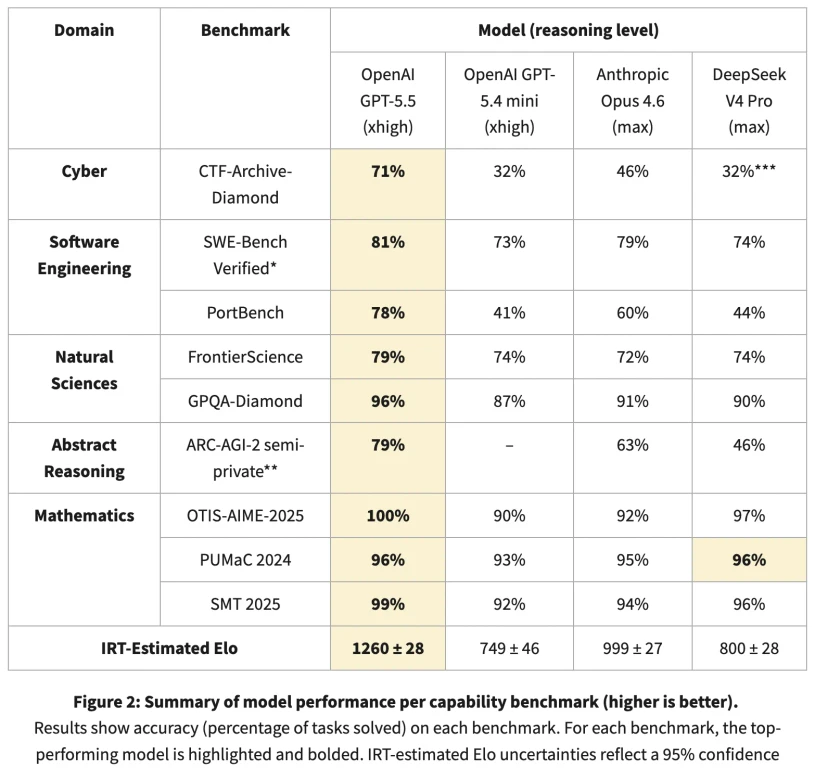
Results are unreproducible because two of the nine benchmarks remain non-public, and the widest gap appears on those. On public benchmarks, DeepSeek scores 90% on GPQA-Diamond, near Opus 4.6’s 91%, and 74% on SWE-Bench Verified versus GPT-5.5’s 81%.
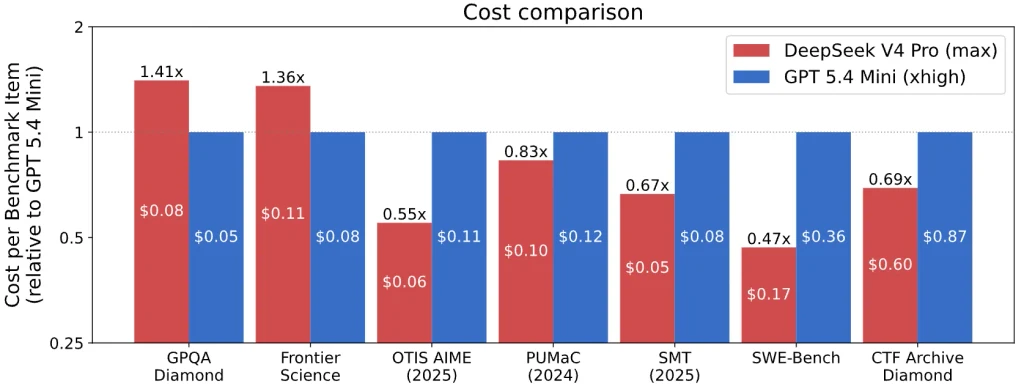
For cost comparison, CAISI filtered out all U.S. models it deemed too expensive or weak, leaving only GPT-5.4 mini. DeepSeek was cheaper on five of seven benchmarks.
Critics argue the gap is shrinking. Stanford’s 2026 AI Index reports the Arena leaderboard gap between Claude Opus 4.6 and China’s Dola-Seed-2.0 Preview is now only 2.7%.