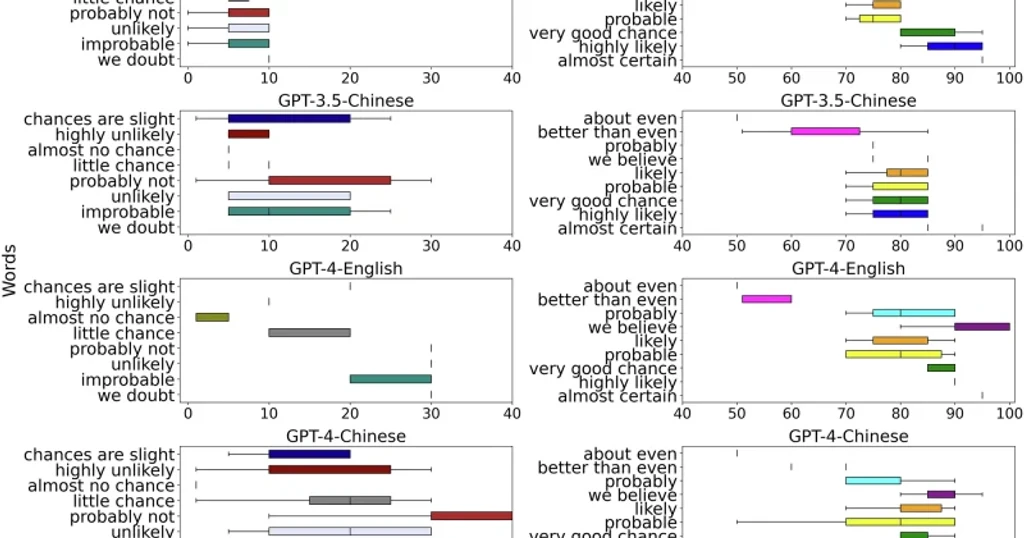
Google Research has released a paper challenging large language models to master a simple but critical skill: expressing uncertainty. The research, “Can Large Language Models Faithfully Express Their Intrinsic Uncertainty in Words?”, reveals that current AI systems are poor at aligning their verbal confidence with their internal certainty. The authors, Gal Yona, Roee Aharoni of Google Research, and Mor Geva, presented the findings at EMNLP 2024.
The paper introduces a metric called “faithful response uncertainty,” which measures the gap between a model's actual confidence-based on its internal probabilistic outputs-and how confidently it phrases its answers. The study focuses on knowledge-intensive question-answering, where models must retrieve and synthesize facts. The recommendation is clear: models should hedge when their internal outputs conflict, using phrases like “I’m not sure, but I think…” instead of asserting uncertain answers as fact.
Current fine-tuning and reinforcement learning techniques often reward models for being definitive, penalizing uncertainty. This dynamic contributes to the persistence of hallucinations. The team argues that aligning expressed uncertainty must become a core training objective, not an afterthought. For professionals relying on AI for critical decisions, this shift could be a game-changer in trust and reliability.