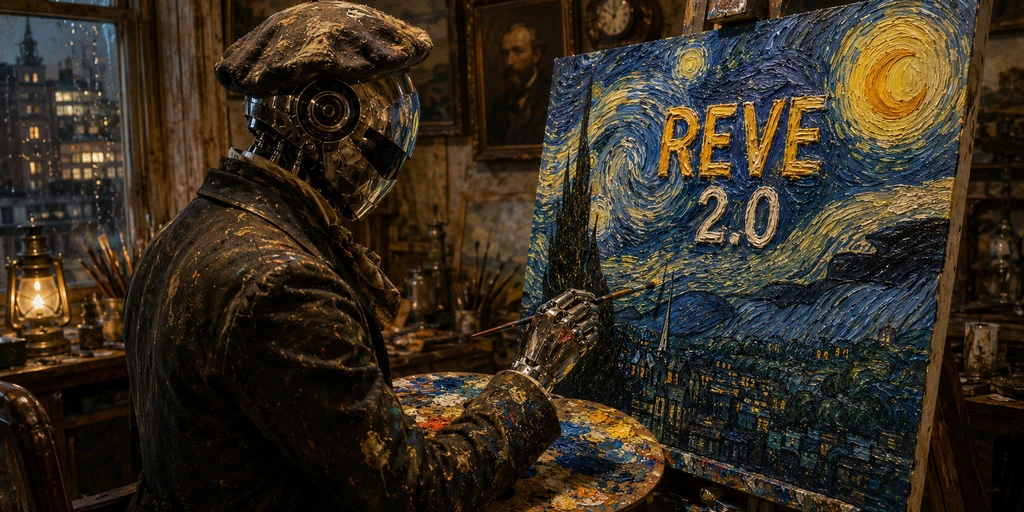
Reve debuted version 2.0 of its AI image model on June 3, immediately ranking second on the Arena text-to-image leaderboard behind OpenAI’s GPT Image 2 and ahead of Google’s Nano Banana 2. The firm achieved the ranking by diverging from standard diffusion methods, instead building a structured, editable layout where every object has a location and caption before rendering.

In testing, the model demonstrated high photorealism, rendering natural skin texture and accurate depth of field at golden hour, though minor flaws persisted in background details. Its spatial awareness proved to be a core strength, handling complex multi-light source prompts with precise object placement.

The headline feature is text rendering. Reve accurately replicated complex storefront signage. While GPT Image 2 surpassed it on micro-text details, Reve produced a smoother and more aesthetically clean final image. For stylized art, it correctly applied a Van Gogh aesthetic while keeping brand text legible, using agentic capabilities to pull an accurate logo from the web.

Agentic generation tasks showed the model can independently plan and execute a complete timeline graphic with consistent styling. In multi-subject editing, it successfully composited two real people into a moon landscape while preserving identity and clothing, though lighting integration was not photorealistic.
For content limits, Reve 2.0 rendered a violent, cinematic battle scene without censorship, whereas competing models from OpenAI and Google either refused or demanded a sanitized prompt.
Reve 2.0 is positioned as the superior tool for iterative professionals requiring high control, high resolution, and low permissiveness. At a fraction of a cent per API call, it drastically undercuts the token pricing of its trillion-dollar competitors, though it occasionally requires manual proofreading for dropped prompt details and lacks absolute fidelity in human editing.